Снижение информационного шума в ИТ-мониторинге с помощью ИИ

Современные ИТ-команды ежедневно сталкиваются с лавиной оповещений: тысячи алертов из десятков систем мониторинга маскируют настоящие угрозы, провоцируя усталость и ошибки. Искусственный интеллект в рамках AIOps превращает этот хаос в четкий поток приоритизированных инцидентов, снижая шум на 80% и ускоряя время реакции.
Что такое информационный шум в ИТ-мониторинге?
Информационный шум в ИТ-мониторинге — это избыточный поток нерелевантных, повторяющихся или ложных оповещений (алертов), который генерируют системы наблюдения за инфраструктурой. Эти инструменты, такие как Zabbix, Prometheus или wiSLA, призваны заранее сигнализировать о потенциальных сбоях, но при огромных объемах — до 10 000 алертов в сутки в крупных компаниях — они превращаются из помощников в источник хаоса: до 83% уведомлений оказываются дубликатами, чувствительными срабатываниями на нормальные колебания или событиями без реального воздействия на бизнес.
Такой шум не просто перегружает операторов: он маскирует критичные инциденты — от деградации платежных систем и DDoS-атак до утечек данных, — повышая риск их пропуска. Например, сбой одного сетевого коммутатора провоцирует каскад из сотен алертов из разных источников, где корневая причина тонет в «фоновом гуле», а команды тратят часы на ручную сортировку вместо оперативного реагирования. В итоге возникает alert fatigue — профессиональное выгорание, когда важные сигналы игнорируются, MTTR растет до 25 часов, а простои в российских компаниях за 2024 год увеличились на 20%.
Основные причины информационного шума
Чрезмерная чувствительность порогов срабатывания
Одной из главных причин избыточных оповещений являются слишком низкие пороги в системах мониторинга. Когда система настроена реагировать на малейшие отклонения метрик, нормальные колебания нагрузки начинают восприниматься как проблема. Например, алерт при использовании CPU выше 70% может быть оправдан для критичной базы данных, но совершенно излишен для сервера обработки фоновых задач в ночное время.
Дублирование оповещений из разных систем
В крупных организациях одновременно функционирует множество инструментов мониторинга — нередко более двадцати различных платформ. Каждая из них отслеживает свой сегмент инфраструктуры, но при возникновении проблемы все системы генерируют собственные уведомления. Так, единичный сбой сетевого коммутатора способен вызвать каскад оповещений от систем мониторинга сети, серверов, приложений и безопасности. В результате инженеры получают сотни уведомлений об одной и той же проблеме.
Отсутствие корреляции и понимания зависимостей
Традиционные системы ИТ-мониторинга не учитывают архитектуру приложений и зависимости между компонентами. Когда падает основной сервер баз данных, десятки зависимых микросервисов начинают сигнализировать о проблемах подключения, хотя корневая причина одна. Без интеллектуальной корреляции специалисты вместо одного понятного инцидента получают лавину алертов без указания первопричины.
Временные аномалии
Микроскачки нагрузки, кратковременные сетевые задержки, автоматические перезапуски сервисов — все эти события генерируют оповещения, которые становятся неактуальными через считанные секунды или минуты. Однако уведомления остаются в системе, требуя ручной проверки и подтверждения. Это отвлекает внимание команды от действительно важных проблем.
Статические правила в динамичной среде
Наборы правил и конфигураций, определяющих когда, как и кому отправлять оповещения, часто заданы месяцы или годы назад. В условиях растущих нагрузок, изменений архитектуры и новых бизнес-процессов такие правила быстро устаревают. То, что было критичным событием для инфраструктуры три года назад, сегодня может стать нормой, но система продолжает сигнализировать. По данным исследований, статические правила становятся причиной до 40% ложных срабатываний в крупных компаниях.
Проблемы интеграции и фрагментация данных
Разрозненные системы ИТ-мониторинга используют разные форматы данных, протоколы передачи и терминологию. Это затрудняет объединение информации в единую картину и приводит к тому, что одно и то же событие описывается по-разному в разных инструментах. Отсутствие централизованной платформы для консолидации и нормализации данных превращает ИТ-мониторинг в набор изолированных информационных «островков».
Влияние на ИТ-команды и управление инцидентами
Избыток оповещений неизбежно сказывается на эффективности ИТ-операций и процессах управления инцидентами. Постоянный поток нерелевантных уведомлений серьезно подрывает как работу команды, так и надёжность систем в целом.
Увеличение времени реакции. Когда инженеры не могут быстро отделить критические проблемы от второстепенных событий, приоритизация реальных инцидентов затягивается. Критические сбои остаются без своевременного реагирования, что ведет к продолжительным простоям и падению операционной эффективности. По некоторым данным, среднее время восстановления возрастает на 30–50% при высоком уровне шума оповещений.
Усталость от оповещений и выгорание. Непрерывный шум притупляет восприятие — команда перестает адекватно реагировать даже на настоящие угрозы. Такая среда стрессовая и демотивирующая, она снижает способность специалистов эффективно работать с реальными проблемами. Выгорание сотрудников не только уменьшает общую продуктивность, но и увеличивает текучесть кадров, что для компании означает дополнительные расходы на подбор и обучение новых людей.
Риск пропуска критических оповещений. Найти важное уведомление среди десятков тысяч ненужных — всё равно что искать иголку в стоге сена. Пропуск критического сигнала ставит под удар стабильность и безопасность ИТ-систем. Последствия могут быть тяжелыми: утечки данных, масштабные сбои сервисов и значительные финансовые потери.
Что такое AIOps?
AIOps, или искусственный интеллект для ИТ-операций, — это применение машинного обучения и анализа данных для автоматизации и оптимизации работы ИТ-отдела. Это не очередной инструмент мониторинга, а интеллектуальный слой, который работает поверх существующих систем.
AIOps-системы обрабатывают большие объемы разнородных данных: логи, метрики, трассировки запросов и заявки на инциденты. Затем к этим данным применяются передовые аналитические методы, позволяющие выявить закономерности и инсайты, которые человеку обнаружить практически невозможно.
Основные компоненты AIOps
AIOps-платформы, такие как Artimate, используют шестиступенчатый подход для эффективного снижения информационного шума. Каждый этап играет ключевую роль в трансформации сырых данных в понятные и действенные инсайты.
1. Консолидация алертов из всех источников
Первый и фундаментальный шаг — сбор оповещений со всей инфраструктуры в единую платформу. Это включает интеграцию различных систем ИТ-мониторинга (Zabbix, WiSLA, Prometheus, Grafana и других). Агрегация данных устраняет изоляцию «островков информации» и создает целостную картину состояния системы. Без этого этапа любая дальнейшая аналитика остается фрагментарной и ограниченной.
2. Фильтрация и нормализация с динамическими порогами
На этом этапе применяется фильтрация нерелевантных событий и приведение форматов к единому стандарту. Вместо статических порогов (например, «CPU > 80%») используются динамические границы, которые адаптируются под текущее поведение системы. Машинное обучение анализирует исторические паттерны и учитывает время суток, нагрузку и сезонность. В результате система перестает сигнализировать о нормальных колебаниях, генерируя предупреждения только при реальных отклонениях от нормы.
3. Дедупликация, объединяющая сотни событий в один
Многие события в ИТ-среде дублируются — одно и то же событие может порождать десятки одинаковых оповещений от разных инструментов. DEDUP-алгоритмы выявляют повторяющиеся уведомления и объединяют их в единый инцидент. Типичная компрессия составляет 85–94%: из тысячи первоначальных алертов команда получает лишь несколько десятков значимых уведомлений. Это радикально снижает объём работы и исключает повторную обработку одних и тех же проблем.
4. Корреляция по структуре, времени и топологии
Интеллектуальная корреляция связывает разрозненные события в логические цепочки, основанные на трех критериях: временная близость, архитектурные зависимости и топология инфраструктуры. Если падает база данных, платформа автоматически группирует связанные оповещения от зависимых микросервисов, сетевых устройств и приложений. В результате вместо сотни отдельных алертов специалисты получают один понятный инцидент с указанием корневой причины.
5. Приоритизация по бизнес-влиянию (SLA, пользователи)
Не все инциденты равнозначны. AIOps оценивает каждое событие с точки зрения его потенциального воздействия на бизнес. Учитываются критические параметры: количество затронутых пользователей, важность сервиса, требования SLA, время суток. Критичный сбой платежного шлюза получит высший приоритет, тогда как проблемы с тестовым окружением будут отложены. Это позволяет команде сосредоточиться на том, что действительно важно для бизнеса.
6. Автоматизация и предиктивная аналитика
Платформа не только фиксирует проблемы, но и предлагает или даже выполняет действия по их устранению. Предиктивная аналитика прогнозирует возможные сбои до их возникновения на основе трендов и паттернов. Сценарии автоматического исправления запускаются без участия человека — например, перезапуск зависшего сервиса или масштабирование ресурсов под пиковую нагрузку. Это снижает операционную нагрузку на команду и минимизирует время простоя.
Результаты внедрения AIOps для снижения информационного шума
Внедрение AIOps-платформ для ИТ-мониторинга дает измеримый эффект на всех уровнях организации — от индивидуальной работы инженера до бизнес-показателей компании в целом. Ниже приведены ключевые результаты, подтвержденные данными отрасли и практическими кейсами.
Сокращение объема оповещений
AIOps-платформы способны фильтровать до 95% нерелевантных уведомлений еще на этапе обработки данных. Это означает, что вместо тысячи алертов в день команда получает лишь несколько десятков значимых инцидентов. Такой уровень фильтрации кардинально снижает информационную нагрузку на специалистов.
Уменьшение времени реакции и восстановления
Интеллектуальная корреляция и приоритизация позволяют сократить среднее время обнаружения и устранения сбоев. Исследования показывают снижение среднего времени восстановления (MTTR) на 30–60%. В некоторых случаях, особенно при автоматическом исправлении повторяющихся проблем, это время сокращается с часов до минут. Более быстрый ответ критично влияет на доступность сервисов и удовлетворенность пользователей.
Снижение количества ложных срабатываний
Статические пороги мониторинга традиционно порождают до 70% ложных алертов. AIOps, применяя динамические базовые линии и анализ контекста, снижает этот показатель до 15–20%. Это освобождает ресурсы команды для работы над реальными задачами, а не для постоянной верификации сигналов.
Повышение продуктивности команд
ИТ-специалисты тратят меньше времени на рутинный анализ и фильтрацию оповещений. По данным DevOps.com, после внедрения AIOps высвобождается до 30% рабочего времени инженеров, которое можно направить на развитие инфраструктуры, улучшение архитектуры и профилактические мероприятия. Снижается нагрузка на дежурные смены и уменьшается риск ошибок из-за усталости.
Улучшение надежности систем
Предиктивная аналитика позволяет выявлять скрытые паттерны и предупреждать об инцидентах до их возникновения. Это ведёт к снижению частоты сбоев и продолжительности простоев. Компании, использующие AIOps, отмечают рост показателей SLA и снижение количества серьезных инцидентов на 40–50%.
Снижение операционных затрат и текучести кадров
Эффективное управление шумами оповещений напрямую влияет на финансовые показатели. Сокращаются расходы на ручной мониторинг, снижается количество простоя бизнес-процессов и уменьшаются затраты на удержание и привлечение специалистов. Выгорание сотрудников уменьшается, так как работа становится более осмысленной и менее стрессовой. Текучесть кадров в ИТ-отделах снижается на 15–20%, что экономит бюджет на обучение новых сотрудников.
Artimate – российская аналитическая AIOps-платформа для ИТ-мониторинга на базе искусственного интеллекта
Российская аналитическая AIOps-платформа Artimate собирает данные со всех систем ИТ-мониторинга и превращает их в сформулированные инциденты с помощью ML-аналитики. Платформа использует технологии искусственного интеллекта и машинного обучения, чтобы отфильтровать лишние оповещения и выделить только действительно важные инциденты. Artimate автоматически коррелирует события из разных систем, обогащает их полезным контекстом, определяет первопричины и выдает рекомендации, снижая нагрузку на персонал и обеспечивая стабильную работу критичных бизнес-сервисов.

Преимущества Artimate:
- Проактивная модель управления IT-сервисами на основе ИИ и машинного обучения;
- Сокращение уровня информационного шума на 95%;
- Оптимизация IT-расходов, которая позволяет IT-командам справляться с ростом данных и инцидентов без расширения штата за счет автоматизации процессов;
- Повышение производительности систем и соответствие SLA 99,99%
- Системный анализ ИТ-ландшафта и выявление узких мест;
- Улучшение клиентского опыта за счет бесперебойной работы сервисов.
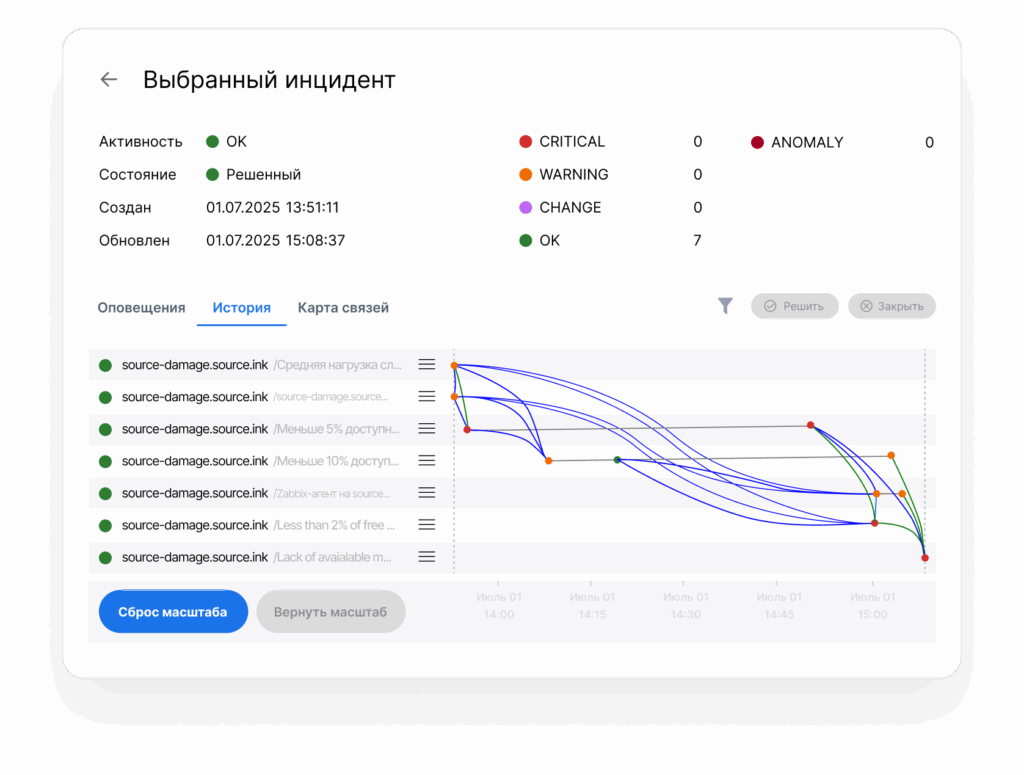
Получите единый интерфейс, в котором собираются данные со всех систем мониторинга, а встроенные инструменты ML-анализа и управления помогают быстро находить причины сбоев, принимать решения и предотвращать инциденты до их влияния на бизнес-сервисы.