Как AIOps помогает улучшить управление ИТ-инфраструктурой

Современные ИТ-системы, состоящие из множества серверов, сетевых устройств, облачных сервисов и приложений, требуют постоянного мониторинга и управления для обеспечения их бесперебойной работы. Однако с увеличением объёма данных, сложности сетевых и вычислительных ресурсов, а также растущими требованиями к скорости реакции на инциденты традиционные методы управления ИТ-инфраструктурой становятся всё менее эффективными.
По данным исследования Gartner, в 2025 году 70% крупных предприятий будут использовать искусственный интеллект для автоматизации ИТ-операций. Это является ответом на растущие потребности бизнеса в более эффективных решениях для обработки данных и быстрого реагирования на события в ИТ-среде. В этом контексте AIOps (Artificial Intelligence for IT Operations) представляет собой ключевую технологию для автоматизации ИТ-операций.
AIOps сочетает в себе возможности искусственного интеллекта и машинного обучения, которые обеспечивают более высокую точность в обнаружении и предсказании инцидентов, уменьшают нагрузку на ИТ-специалистов и помогают ускорить процесс принятия решений.
В этой статье мы рассмотрим, как AIOps помогает улучшить управление ИТ-инфраструктурой, и какие преимущества оно приносит бизнесам, сталкивающимся с вызовами современного цифрового мира.
Что такое AIOps?
Первое определение термина AIOps было предложено в 2016 году компанией Gartner. В своём исследовании, опубликованном в том же году, Gartner представил AIOps как концепцию, которая объединяет искусственный интеллект и машинное обучение с традиционными процессами управления ИТ-операциями. Компания описала AIOps как платформу, использующую эти технологии для автоматизации, мониторинга, обнаружения аномалий, диагностики и принятия решений, с целью оптимизации и улучшения управления ИТ-инфраструктурой.
Основная цель AIOps — объединить в единую систему данные о всех компонентах ИТ-инфраструктуры и бизнес-сервисах, предоставляя автоматические инструменты для локализации, диагностики и устранения проблем. В отличие от традиционного подхода, когда на решение проблем уходит много времени и требуются значительные человеческие усилия, AIOps позволяет делать это с помощью ML-алгоритмов, которые быстро и точно обнаруживают проблемы и устраняют их до того, как они успевают повлиять на работу бизнеса.
Важным аспектом AIOps является его способность к самообучению и улучшению с течением времени. Благодаря использованию машинного обучения, системы AIOps могут анализировать историю инцидентов, выявлять паттерны и предсказывать возможные сбои или угрозы. Таким образом, AIOps не только помогает оперативно устранять проблемы, но и предотвращать их, что значительно повышает надежность и эффективность работы всей ИТ-инфраструктуры.
Внедрение AIOps также способствует более высокому уровню автоматизации, уменьшению операционных расходов и повышению безопасности за счет более более быстрого и точного реагирования на инциденты. Всё это делает AIOps ключевым элементом в стратегиях цифровой трансформации организаций, где скорость, гибкость и эффективность имеют первостепенное значение.
Проблемы традиционного подхода к управлению ИТ-инфраструктурой

С развитием технологий и существенным увеличением объёмов данных традиционные методы управления ИТ-инфраструктурой становятся всё менее эффективными. В частности, старые подходы, основанные на ручном мониторинге, фиксированных алгоритмах и преобладании человеческого участия в процессе диагностики и реагирования на инциденты, не справляются с растущими вызовами, которые предъявляют современные вычислительные и сетевые технологии. Рассмотрим основные проблемы, с которыми сталкиваются компании при использовании традиционных методов управления ИТ-инфраструктурой:
Избыточность и неэффективность
Традиционные подходы управления ИТ-инфраструктурой часто требуют от специалистов выполнения множества повторяющихся задач, таких как мониторинг систем, анализ больших объёмов данных и реагирование на инциденты. При этом в большинстве случаев каждый инструмент, используемый для мониторинга или диагностики, работает независимо, без интеграции с другими системами. Это приводит к избыточности в данных, потому что одна и та же информация может собираться и анализироваться различными системами, а также увеличивает вероятность ошибок из-за разной интерпретации данных.
К тому же традиционные системы часто не способны предоставить полную картину происходящего в реальном времени, требуя значительных усилий для объединения данных с разных источников и инструментов. Это снижает общую эффективность работы ИТ-отдела и увеличивает вероятность пропуска критичных инцидентов.
Трудности с масштабируемостью
С увеличением объёма данных, поступающих от устройств, приложений, цифровых сервисов и услуг, компании сталкиваются с проблемой масштабируемости своих ИТ-операций. В условиях быстрого роста и расширения инфраструктуры, будь то облачные решения, IoT-устройства или новые вычислительные ресурсы, традиционные методы управления становятся всё более громоздкими. ИТ-отделам необходимо постоянно увеличивать количество специалистов и инструментов для поддержания системы, что не только увеличивает затраты, но и делает систему сложной для управления.
Масштабирование традиционных решений требует значительных усилий, а также наличия специалистов, способных эффективно адаптировать процессы и инструменты к новому уровню сложности. Всё это затрудняет быстрое принятие решений и оперативную настройку системы, что критично в условиях динамичного бизнеса.
Проблемы с обнаружением инцидентов
Одной из самых серьёзных проблем традиционного подхода является медленное обнаружение инцидентов и угроз. При отсутствии интеграции между системами мониторинга и аналитики, а также при недостаточной автоматизации, инциденты могут оставаться незамеченными до тех пор, пока не приведут к значительному сбою в работе инфраструктуры.
Мониторинг может выявлять только явные проблемы, такие как перегрузки серверов или сбои в сети, но не может предсказать или выявить скрытые проблемы, такие как уязвимости в безопасности или недочёты в производительности, которые могут развиваться с течением времени. Это приводит к значительным потерям, особенно в критических сферах, таких как финансовые операции или медицинские сервисы.
Задержки в принятии решений
В традиционных системах, где значительная часть задач ложится на плечи ИТ-специалистов, время реагирования на инциденты или проблемы часто становится затруднённым из-за множества этапов и человекоцентрированных процессов. Когда специалисту необходимо вручную собрать данные, провести диагностику и принять решение, могут возникать задержки, что повышает риск того, что проблема перерастёт в серьёзный инцидент.
Например, если система мониторинга обнаруживает отклонение от заданного порога, но специалист не успевает оперативно отреагировать или не имеет достаточного контекста для принятия решения, это может привести к длительному времени простоя, финансовым потерям или нарушению репутации компании.
Человеческие ошибки и перегрузка сотрудников
Несмотря на высокую квалификацию ИТ-специалистов, человеческий фактор остаётся важной проблемой в традиционном подходе к управлению ИТ-операциями. Большой объём работы, многочасовые нагрузки и стресс могут привести к ошибкам. Люди не всегда могут эффективно справляться с рутинными задачами или анализом огромных объёмов данных, что увеличивает риск ошибок, например, неверной настройки системы или неправильной диагностики инцидента.
Кроме того, перегрузка специалистов, работающих с устаревшими системами, может привести к снижению их производительности и снижению качества обслуживания пользователей, что в долгосрочной перспективе влияет на репутацию компании.
Ограниченные возможности для прогнозирования проблем
Традиционные методы ИТ-мониторинга ориентированы на реакцию на уже возникшие проблемы, но не на их предсказание или предотвращение. Даже если система эффективно выявляет текущие инциденты, она не всегда способна предупредить об угрозах, которые могут возникнуть в будущем, или о проблемах, развивающихся медленно и незаметно. Это создаёт риск того, что компания будет реагировать на инциденты только после того, как они уже окажут негативное воздействие на её работу.
Для предотвращения проблем, таких как сбои в системах, перегрузки или даже утечка данных, требуются системы, которые способны анализировать исторические данные, выявлять паттерны и предсказывать возможные сбои заранее.
Как AIOps решает эти проблемы?

AIOps кардинально меняет парадигму управления ИТ-операциями, внедряя элементы искусственного интеллекта и машинного обучения для анализа и обработки больших объёмов данных из разных источников в реальном времени.
В отличие от традиционных инструментов мониторинга, которые работают разрозненно и предоставляют фрагментарную картину, AIOps формирует целостную экосистему управления инфраструктурой, позволяя решать ключевые проблемы, с которыми сталкиваются ИТ-команды.
Ниже приведены основные способы, с помощью которых AIOps устраняет недостатки классических подходов.
Интегрированный сбор и корреляция данных
Одной из главных сложностей при использовании традиционных систем мониторинга является большое число инструментов и источников, данные из которых практически не пересекаются между собой. AIOps-платформы устраняют этот «разрозненный» подход за счёт:
- Единой точки сбора. Система агрегирует информацию со всех уровней ИТ-инфраструктуры — от аппаратной части и виртуальных машин до облачных сервисов и микросервисных приложений.
- Корреляции событий. AIOps «сшивает» данные из разных подсистем. Например, если в сетевой инфраструктуре увеличивается задержка, одновременно с этим растёт нагрузка на базу данных и появляются ошибки в логах, платформа свяжет все эти инциденты, распознает общий корень проблемы и оценит её влияние на работу ключевых сервисов.
В результате сокращается дублирование данных, повышается точность диагностики, а специалисты видят единую картину состояния инфраструктуры, не тратя время на переключение между несколькими инструментами.
Автоматизированное обнаружение аномалий
Традиционные системы мониторинга чаще всего опираются на статические пороги (thresholds), которые не учитывают динамические изменения в поведении систем и сезонность нагрузок. В результате ИТ-команды либо получают слишком много ложных срабатываний, либо пропускают критические инциденты. AIOps решает эту проблему следующим образом:
- Алгоритмы машинного обучения. Система изучает поведение сервисов в разные периоды времени (например, дневная и ночная нагрузка, сезонные пики), формирует динамические модели «нормы» и выявляет реальные отклонения.
- Интеллектуальная фильтрация. Вместо бесчисленных сигналов о мелких проблемах, AIOps умеет агрегировать связанные события, распознавать паттерны и формировать осмысленные предупреждения. Таким образом, команде не приходится бороться с «шумом» в виде сотен несвязанных уведомлений.
В результате существенно снижено количество пропущенных инцидентов и уменьшена «шумовая» нагрузка на ИТ-специалистов. Система способна не только обнаруживать «моментальные» сбои, но и замечать постепенные отклонения, ведущие к более серьёзным проблемам в будущем.
Предиктивная аналитика и проактивное предотвращение проблем
Одно из ключевых отличий AIOps от традиционных инструментов заключается в умении не просто реагировать на инциденты, а предугадывать их:
- Предсказание загрузки. Платформа на основе исторических данных и трендов способна спрогнозировать, когда определённый ресурс (процессор, память, дисковое пространство) достигнет своего лимита. Это позволяет заранее оптимизировать конфигурацию или добавить ресурсы.
- Выявление реляционных зависимостей. AIOps анализирует множество метрик и логов, чтобы понять, как изменения в одном сервисе влияют на смежные компоненты. К примеру, если объём клиентских запросов в веб-приложении растёт, система предсказывает нагрузку на базу данных и балансировщики.
В результате компании переходят от реактивной модели управления («сбой — поиск решения — устранение») к проактивной («обнаружение риска — предупреждающие действия — предотвращение сбоев»), что сокращает время простоя и повышает стабильность всей ИТ-среды.
Автоматизированное реагирование на инциденты
В традиционных сценариях при обнаружении проблемы инженерам приходится вручную выполнять серию действий: собрать данные, провести диагностику, перезапустить сервис, изменить конфигурацию и т. д. При большом количестве инцидентов или при возникновении серьёзной проблемы это приводит к существенным задержкам и человеческим ошибкам. AIOps автоматизирует эти процессы:
- Runbooks. Сценарии реагирования, которые запускаются автоматически или после подтверждения инженером. Например, при достижении определённого порога загрузки система может «на лету» масштабировать ресурсы в облаке.
- Интеграция с DevOps. Современные AIOps-платформы легко «встраиваются» в инфраструктуру, используя API-интерфейсы и плагины для CI/CD-инструментов, систем управления тикетами (Jira, ServiceNow) и других сервисов.
В результате время на устранение сбоев сокращается в разы, а уровень человеческого вмешательства уменьшается, что позволяет ИТ-командам уделять больше внимания развитию и улучшению сервисов.
Оптимизация и приоритизация оповещений
Ещё одна распространённая боль классического мониторинга — шквал оповещений, из которых сложно выделить ключевые. Сильнее всего это ощущается в крупных компаниях, где инфраструктура насчитывает сотни и тысячи взаимосвязанных сервисов. AIOps использует механизмы интеллектуальной фильтрации:
- Агрегация и корреляция событий. Вместо десятков оповещений о проблемах, возникающих из одного и того же инцидента (например, сбой сервиса, который «тянет» за собой зависимые процессы), система группирует их в единый тикет, указывая на общую причину.
- Бизнес-контекст. Инциденты распределяются по приоритетам с учётом значимости затронутого сервиса для бизнеса. Например, сбой, влияющий на критические финансовые транзакции, помечается как приоритет №1.
В результате ИТ-специалисты концентрируются на действительно важных инцидентах и быстрее принимают меры, не растрачивая время на анализ «шума».
Улучшенная диагностика первопричин (Root Cause Analysis)
Для оперативного и эффективного устранения инцидентов важно не только вовремя заметить проблему, но и понять её основную причину. В традиционных системах для этого часто требуется построение ресурсно-сервисной модели и ручной анализ, который может занимать часы, а то и дни. AIOps упрощает процесс корневой диагностики:
- Мультисценарная корреляция. Платформа в режиме реального времени сопоставляет события, логи и метрики, формируя цепочку зависимостей. Например, если один из серверов базы данных сталкивается с перегрузкой ЦП, система тут же проверяет журналы приложений, сетевые события и нагрузки смежных сервисов.
- Анализ исторических данных. Алгоритмы машинного обучения учитывают прошлые инциденты, их причины и пути решения. Это позволяет системе выдавать рекомендации, основанные на ранее выявленных паттернах.
В результате корневая причина инцидента находится быстрее, а риск повторных сбоев снижается благодаря накопленной базе знаний.
Масштабируемость и гибкость управления
Современная ИТ-инфраструктура развивается стремительно: появляются новые облачные сервисы, микросервисная архитектура, IoT-устройства. Традиционные инструменты мониторинга и управления зачастую не успевают за темпами изменений. AIOps изначально проектируется с учётом масштабируемости:
- Облачная архитектура. Большинство AIOps-решений легко интегрируются с публичными и частными облаками, где возможно быстрое наращивание мощностей хранения и обработки данных.
- Контейнеризация и микросервисы. Платформы AIOps ориентированы на контейнерные оркестраторы (Kubernetes), что позволяет автоматически подключать новые сервисы и анализировать их метрики без сложных ручных настроек.
В результате организации быстро адаптируют систему мониторинга под растущую инфраструктуру и меняющийся стек технологий, не теряя в качестве и скорости анализа.
Сокращение человеческого фактора и повышение квалификации команды
Человеческие ошибки, перегрузка ИТ-специалистов рутинными задачами, нехватка времени на стратегическое планирование — всё это характерно для «ручного» управления ИТ-операциями. AIOps позволяет решить эти проблемы:
- Автоматизация рутинных задач. Система берёт на себя обработку сигналов мониторинга, первичную диагностику, запуск скриптов устранения инцидентов, тем самым высвобождая время специалистов для творческой работы и развития новых функций.
- Повышение экспертизы. Инженеры начинают работать с более глубокими вопросами архитектуры и улучшений, строить новые процессы, изучать тонкости машинного обучения, что повышает общий уровень команды.
В результате снижается вероятность «человеческого фактора» в сбоях, а также повышается качество управления благодаря более мотивированным и квалифицированным сотрудникам.
В целом, AIOps позволяет перейти к принципиально новому уровню зрелости ИТ-операций. Вместо традиционной модели, где специалисты тратят большую часть времени на реагирование и ручные проверки, компании начинают проактивно управлять инфраструктурой, предотвращать сбои и улучшать пользовательский опыт, выполнять системный анализ проблем. Всё это в совокупности ведёт к снижению затрат, повышению надёжности сервисов и ускорению цифровой трансформации бизнеса.
Преимущества внедрения AIOps в управление ИТ-инфраструктурой
AIOps даёт компаниям целый ряд преимуществ, позволяя перевести управление ИТ-инфраструктурой на качественно новый уровень. Ниже мы рассмотрим основные выгоды, которые получают организации при использовании AIOps-платформ.
Существенное сокращение времени простоя (downtime)
В условиях цифровой экономики каждой минуте простоя соответствует потеря прибыли, ухудшение пользовательского опыта и репутационные риски для бизнеса. AIOps решает эту проблему благодаря:
- Быстрому обнаружению инцидентов
Алгоритмы машинного обучения и интеллектуальная аналитика позволяют мгновенно выявлять аномалии и потенциальные сбои в работе сервисов. Это сокращает среднее время обнаружения проблемы (MTTD) и даёт специалистам фору в устранении неполадок. - Автоматическому реагированию
AIOps-платформы способны не только сообщать о проблемах, но и предлагать решения, запускать готовые сценарии (runbooks) для быстрого исправления инцидентов. Например, при обнаружении перегрузки сервера система может автоматически перераспределить нагрузку или масштабировать ресурсы, сводя к минимуму время простоя. - Проактивной диагностике
Предиктивная аналитика AIOps «видит» заранее, когда ресурс близок к исчерпанию или начинают появляться сбои, и предупреждает об этом. Благодаря этому команда может принять меры до того, как проблема перерастёт в крупный инцидент.
Итог: уменьшение среднего времени восстановления (MTTR) и снижение финансовых и репутационных потерь, связанных с простоями.
Сокращение операционных издержек
Эксплуатация сложной ИТ-инфраструктуры обходится дорого, особенно если большая часть времени и ресурсов уходит на ручной труд и устранение повторяющихся проблем. Внедрение AIOps помогает в:
- Оптимизации трудозатрат
Рутинные операции, такие как анализ лог-файлов, ручная диагностика и мелкие исправления, автоматизируются. Высвобожденное время сотрудники могут направить на стратегические задачи: развитие архитектуры, внедрение новых сервисов, повышение уровня безопасности. - Снижении затрат на перерасход ресурсов
AIOps анализирует метрики использования CPU, памяти, сетевых ресурсов и т. д., выявляя узкие места и избыточные мощности. Это помогает грамотно перераспределять ресурсы или вовремя освобождать их, не платя за «простой» оборудования и облачных сервисов. - Предотвращении крупномасштабных сбоев
Избежав серьёзных аварий (или хотя бы минимизировав их последствия), компании экономят не только на ремонте и восстановлении, но и на дополнительных штрафах, компенсациях и потере лояльности клиентов.
Итог: сокращаются прямые операционные расходы и косвенные убытки, что положительно сказывается на общей рентабельности (ROI) проектов в области ИТ.
Повышение точности и скорости реагирования
При традиционном управлении инфраструктурой сотрудники часто получают избыточный поток уведомлений, из которых нужно оперативно вычленить действительно важные сигналы. AIOps здесь незаменим:
- Умное шумоподавление
Платформа автоматически «чистит» шум — обрабатывает большие потоки логов и метрик, группирует похожие события и приоритизирует их с учётом бизнес-критичности. Это даёт возможность сосредоточиться на инцидентах, которые представляют реальную угрозу для инфраструктуры или пользователей. - Корреляция инцидентов
AIOps не только указывает на наличие проблемы, но и связывает её с возможной первопричиной, учитывая контекст системы. В результате специалисты быстрее находят «узкое место» и устраняют его, не растрачивая время на повторную проверку смежных компонентов. - Интеграция с ITSM и DevOps-инструментами
Благодаря готовым коннекторам и API, AIOps-платформы нативно взаимодействуют с системами управления инцидентами (ServiceNow, Jira) и CI/CD-конвейерами. Автоматическая передача данных о проблемах и корректирующих действиях ускоряет процесс реагирования в несколько раз.
Итог: команда тратит меньше сил на ручную фильтрацию уведомлений и быстрее устраняет инциденты, фокусируясь на корневых проблемах вместо «латания» отдельных проявлений.
Прогнозирование и проактивное устранение проблем
Ключевое отличие AIOps от классических инструментов — способность предугадывать потенциальные проблемы:
- Анализ исторических паттернов
Система изучает изменения метрик за длительный период: всплески трафика, пики нагрузки, характерные сбои и т. д. На основе выявленных закономерностей формируются динамические модели, позволяющие предвидеть, когда и где может произойти сбой. - Прогноз ресурсных ограничений
AIOps оценивает текущие тренды в потреблении ресурсов и даёт рекомендации: где нужно масштабирование, а где ресурсы, напротив, используются с избытком. Это важно для оптимизации затрат, особенно в гибридных и облачных средах. - Проактивные меры
Когда система «видит», что ситуация развивается по негативному сценарию (например, увеличивается время отклика в базе данных, растёт очередь запросов), она может заранее запустить корректирующие сценарии или предупредить команду о необходимости вмешательства.
Итог: бизнес получает возможность перейти от реактивной модели к проактивной, избегая критичных ситуаций и обеспечивая более стабильную работу сервисов.
Масштабируемость и гибкость
Современная инфраструктура динамична: она может включать в себя и локальные дата-центры, и облачные площадки, и контейнеризированные приложения. AIOps «растёт» вместе с нагрузкой:
- Поддержка облака и гибридных сред
AIOps-платформы позволяют унифицировано мониторить и управлять сервисами, находящимися в разных окружениях). Это особенно важно при быстрой экспансии или миграции части сервисов между разными средами. - Гибкая архитектура
Большинство AIOps-решений — модульные и распределённые. Это даёт возможность безболезненно наращивать мощности анализа и хранения данных, не перестраивая всю систему мониторинга с нуля. - Контейнеризация и микросервисы
AIOps легко интегрируется со средствами оркестрации, что позволяет автоматически отслеживать новые микросервисы и поддерживать их жизненный цикл, даже когда их число быстро растёт.
Итог: компании могут быстро масштабировать инфраструктуру и инструменты мониторинга, не теряя в качестве аналитики и управляемости.
Улучшение взаимодействия внутри команды
В крупных организациях управление ИТ-инфраструктурой затрагивает сразу несколько отделов: DevOps, системных администраторов, специалистов по безопасности, разработчиков. AIOps помогает гармонизировать их взаимодействие:
- Единое информационное поле
Данные о состоянии систем, логах, метриках и инцидентах хранятся в одном месте. Каждая команда видит общий контекст и может принимать решения, основываясь на достоверных, согласованных данных. - Автоматическая постановка задач
При возникновении проблемы система может автоматизированно создавать тикет в Jira или ServiceNow и назначать ответственное лицо. Таким образом, сокращается время на ручное «перекидывание» задач и улучшается прозрачность. - Обучение и обмен опытом
Поскольку AIOps формирует базу знаний по инцидентам и сценариям их решения, новые сотрудники быстрее погружаются в специфику инфраструктуры, а опытные специалисты получают удобный инструмент для обучения коллег.
Итог: повышается согласованность между отделами и уменьшается количество конфликтов и недопонимания, что в конечном счёте отражается на качестве и скорости обслуживания.
Усиление информационной безопасности
Хотя AIOps обычно связывают с управлением производительностью и надёжностью систем, он также вносит вклад в обеспечение кибербезопасности:
- Выявление подозрительных паттернов
AIOps-алгоритмы могут фиксировать и сообщать о нехарактерном поведении пользователей, сервисов или компонентов сети. Это позволяет вовремя обнаруживать потенциальные угрозы, такие как взлом, утечка данных или вредоносная активность. - Корреляция событий безопасности
Платформа сопоставляет логи из SIEM-систем с данными мониторинга ИТ-инфраструктуры. Например, резкий скачок в сетевом трафике, сопровождающийся нетипичными запросами к БД, может указывать на попытку атаки. - Интеграция с SOC
AIOps-решения могут передавать информацию о подозрительных событиях в Центр мониторинга безопасности (SOC), облегчая работу аналитиков и сокращая время реагирования на инциденты.
Итог: улучшенная видимость и своевременная реакция на потенциальные уязвимости укрепляют общую безопасность бизнеса.
Повышение конкурентоспособности и ROI
В условиях жёсткой конкуренции и быстрого развития технологий умение поддерживать стабильность и высокую производительность ИТ-сервисов напрямую отражается на успехе компании:
- Опережение конкурентов
Компании, использующие AIOps, способны быстрее адаптироваться к изменяющимся требованиям рынка, запускать новые сервисы и оптимизировать существующие. Это даёт им конкурентное преимущество по времени выхода на рынок (time-to-market). - Прозрачная оценка эффективности
AIOps предоставляет метрики, которые можно использовать для расчёта ROI: снижение числа инцидентов, экономия человеческих ресурсов, увеличение времени безотказной работы сервисов. Всё это позволяет бизнесу чётко увидеть, как инвестиции в AIOps окупаются. - Поддержка цифровой трансформации
Для компаний, идущих по пути цифровизации, AIOps становится фундаментом, на котором легко строить новые инициативы (Big Data, IoT, AI-продукты и т. д.), потому что инфраструктура управляется более надёжно и гибко.
Итог: внедрение AIOps ускоряет развитие бизнеса, улучшает финансовые результаты и даёт ощутимые конкурентные преимущества.
Как выбрать подходящую платформу AIOps для бизнеса?

Переход на AIOps — серьёзное стратегическое решение, от которого во многом зависит успешное управление ИТ-инфраструктурой. Выбор конкретной платформы AIOps необходимо осуществлять с учётом бизнес-целей, особенностей существующей инфраструктуры и функциональными особенностями новой платформы.
Определение бизнес-целей и приоритетов
Перед тем как сравнивать различные продукты, важно понять, для каких целей и задач необходима платформа AIOps. Сформулируйте, чего вы хотите достичь: снизить время простоя, ускорить поиск первопричин, повысить безопасность, сократить расходы на поддержку и т.д. Если в фокусе проактивное обнаружение и предотвращение инцидентов, ищите платформу с сильным функционалом предиктивной аналитики и машинного обучения.
В каких отраслях работает компания, с какими требованиями к надёжности, безопасности и скорости она сталкивается? Например, финансовый сектор требует повышенной безопасности и строгих SLA, а ритейл — высокой гибкости и скорости масштабирования.
Если планируется масштабное расширение инфраструктуры, интеграция с мультиоблачными средами или микросервисной архитектурой, необходимо заранее убедиться, что платформа справится с такими нагрузками и сможет «расти» вместе с бизнесом.
Анализ текущей инфраструктуры и инструментов
Для эффективной интеграции AIOps-платформы важно учесть уже имеющийся стек технологий:
Существующие системы мониторинга
В компании могут быть развёрнуты классические инструменты (Zabbix, Prometheus и др.), а также лог-менеджеры или SIEM-системы. Платформа должна безболезненно интегрироваться с ними, объединяя данные в единую точку обзора.
Облачная или локальная среда
Уточните, где физически находится инфраструктура: в публичном облаке (, в частном облаке, локальном ЦОД или в гибридном варианте. AIOps-платформа должна поддерживать ваш сценарий развертывания и иметь коннекторы (агенты) для быстрого сбора метрик и логов.
Объём данных и пиковая нагрузка
Оцените, как много данных необходимо обрабатывать и какой ожидается пик нагрузки . Платформа должна быть готова к такому потоку, не теряя производительность и оперативность.
Ключевые функциональные возможности
AIOps — это не просто набор инструментов мониторинга, а комплексное решение, сочетающее машинное обучение, автоматизацию и аналитику больших данных. Обратите внимание на следующие аспекты:
Обнаружение аномалий и предиктивная аналитика
Насколько глубоко платформа может анализировать исторические паттерны, выявлять аномалии и предсказывать потенциальные инциденты? Наличие обучаемых алгоритмов и искусственного интеллекта критически важно для получения «умной» аналитики.
Корреляция событий и шумоподавление
Ищите решения, способные объединять разрозненные сигналы и события в единую картину. Это существенно сокращает «шум» и помогает быстрее находить первопричину проблем.
Автоматизация реагирования (runbooks, playbooks)
Проверьте, готова ли платформа предлагать решения и запускать сценарии эскалации для автоматического устранения неисправностей или масштабирования. Чем выше уровень автоматизации, тем быстрее время реакции и тем меньше рутины ложится на ИТ-специалистов.
Гибкое построение дашбордов
Удобные визуальные панели помогают оперативно оценивать состояние системы, а интеграция бизнес-метрик с техническими позволяет выстраивать прозрачную связь между ИТ и бизнесом.
Возможности масштабирования
Решение должно поддерживать десятки тысяч объектов мониторинга и справляться с многопоточными нагрузками, сохраняя стабильную производительность.
Составьте список функционала, который необходим именно вашей компании, и сверяйте его со спецификациями потенциальных платформ, чтобы выбрать максимально подходящую.
Artimate: ведущая российская AIOps-платформа для управления IT-ландшафтом
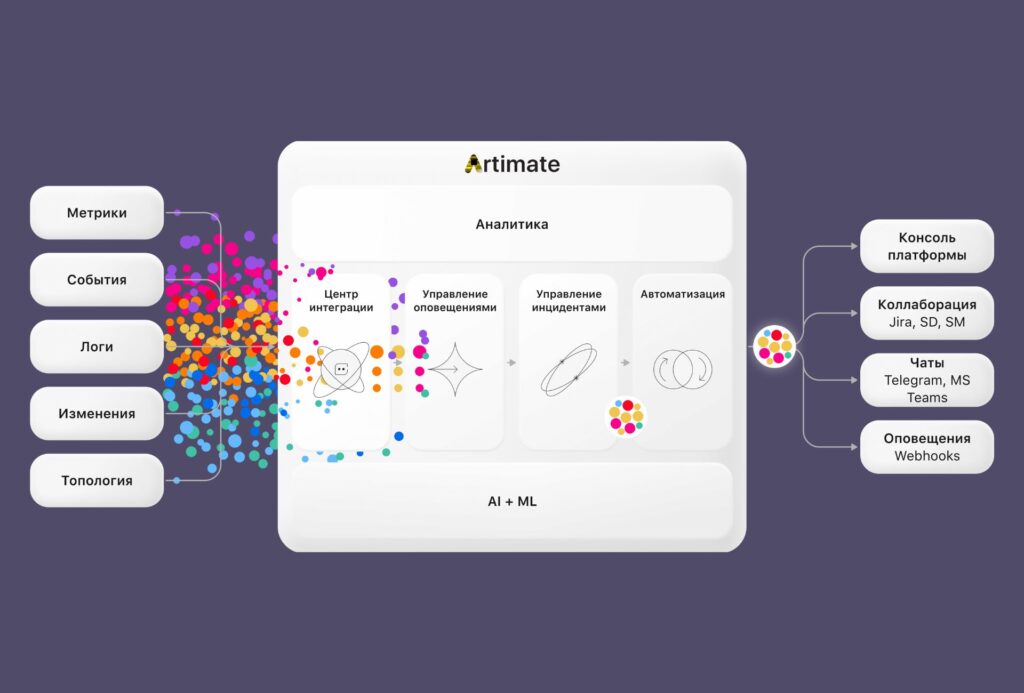
Российская AIOps-платформа Artimate
Artimate — это современная российская AIOps-платформа, разработанная для управления сложной IT-инфраструктурой. Она объединяет данные из множества источников, снижает уровень информационного шума, автоматизирует решение инцидентов и предлагает проактивный подход к управлению ИТ-сервисами, используя технологии ИИ и ML.
Artimate создана российскими разработчиками компании ProofTech IT с учётом потребностей российского рынка. В отличие от open-source решений, платформа предлагает профессиональную поддержку, готовые интеграции с популярными системами мониторинга и полное соответствие требованиям импортозамещения.
Преимущества AIOps-платформы Artimate
Снижение информационного шума
Благодаря встроенным механизмам фильтрации и дедупликации Artimate сокращает поток уведомлений на более чем 99%, позволяя команде сосредоточиться на критически важных задачах.
Интеллектуальный анализ и автоматизация
Artimate использует алгоритмы машинного обучения для выявления аномалий, поиска первопричин и прогнозирования инцидентов. Платформа автоматически анализирует корреляции между событиями, что помогает оперативно выявлять и устранять корневые причины.
Проактивный мониторинг
Платформа не только фиксирует текущие проблемы, но и прогнозирует потенциальные сбои, обеспечивая надёжность работы IT-сервисов даже при высоких нагрузках.
Централизованное управление
Интуитивно понятный интерфейс объединяет данные из различных источников, предоставляя единую панель для мониторинга, анализа и управления. Это исключает разрозненность систем и повышает эффективность.
Широкая интеграция
Artimate легко интегрируется с такими популярными системами (например, Zabbix) и ITSM-решениями. Встроенные инструменты позволяют быстро настроить новые источники данных, минимизируя время внедрения.
Системный анализ
Платформа предлагает готовые инструменты для комплексного анализа проблем, причинно-следственных связей, поиска и устранения узких мест.
Почему стоит выбрать Artimate?
Платформа Artimate предназначена для крупных корпораций с географически распределённой и динамически развивающейся IT-инфраструктурой. Решение ориентировано на бизнесы, где важны скорость, надёжность и прозрачность IT-процессов.
Artimate — это:
- Полное соответствие российским требованиям;
- Снижение зависимости от экспертов за счёт автоматизации рутинных процессов;
- Значительное сокращение времени на решение инцидентов (MTTR);
- Расширенные возможности ML-аналитики для выявления скрытых смыслов;
- Повышение стабильности IT-сервисов и соблюдение SLA.
Artimate — это не просто инструмент, а стратегическое решение для цифровой трансформации. Платформа не только упрощает управление IT-ландшафтом, но и позволяет компании сосредоточиться на своих основных задачах, устраняя технологические барьеры.
Протестируйте Artimate уже сегодня — закажите демонстрацию и убедитесь в её эффективности!