Интеллект против Big Data в ИТ-мониторинге: от тушения пожаров к умному управлению

Современный мир представляет собой сложную систему, в которой физические законы и явления эмерджентности создают огромное количество данных. Чтобы эффективно адаптироваться и действовать в таких условиях, необходимы передовые методы анализа и упрощения информации.
Основной вызов заключается в следующем: элементы системы взаимодействуют между собой по определённым, не всегда очевидным закономерностям. Прямо наблюдать эти взаимосвязи невозможно — нам остаётся лишь анализировать информационные следы, которые они оставляют, и строить гипотезы о стоящих за ними механизмах.
В данной статье мы раскроем ключевые проблемы и подходы к управлению масштабной IT-инфраструктурой и поделимся нашим опытом.
Мониторинг ИТ-инфраструктуры — лишь один из примеров
Мониторинг применим не только в IT-сфере — аналогичные задачи могут быть поставлены для больниц, коммерческих компаний, исследования вашего поведения или разработки научных теорий. Даже если система создана человеком, неполнота данных и случайности внешнего мира со временем приводят к тому, что наше понимание её работы всё больше отходит от реальности.
Поэтому важно использовать интеллектуальные подходы к мониторингу. Это значит не просто анализировать отдельные события или их статистику, а сосредотачиваться на высокоуровневых состояниях системы и их переходах. Так можно заново собрать целостное представление о системе и глубже понять её динамику.
Сложность современной серверной инфраструктуры
Каждая современная компания, от небольшого стартапа до гиганта индустрии, опирается на IT-инфраструктуру разной сложности. Система состоит из множества серверов, сетей, приложений и сервисов, которые должны безупречно взаимодействовать друг с другом. Чем больше компания, тем сложнее становится её инфраструктура, и тем больше компонентов должны функционировать слаженно, порождая экспоненциальный рост связей между компонентами.
Но наблюдать за всем этим напрямую — задача не из лёгких. В реальном времени мы можем отслеживать лишь «подсказки» — метрики, логи и триггеры (уведомления о событиях). И вот тут начинается мониторинг: превращение тонн низкоуровневых сигналов в высокоуровневые представления, которые помогают людям понимать систему целиком. Ведь с помощью только одних триггеров не справиться с действительно большими объёмами событий, в лучшем случае для этого понадобится много ручного труда.
Эмерджентное поведение больших систем
Одной из ключевых особенностей работы с такими системами является эмерджентное поведение — когда взаимодействие отдельных компонентов создаёт неожиданные результаты, неочевидные при анализе каждого элемента отдельно. С ростом сложности системы вероятность появления таких эффектов значительно возрастает. IT-инфраструктура, с ее динамическими изменениями и множеством независимых сервисов, является ярким примером подобной среды. Управление такой системой — это всегда работа с неизбежными неожиданностями.
Понимание вызовов и решений в мониторинге IT-инфраструктуры

Неизбежность: масштабируемость и сложность
Представьте себе динамично развивающуюся компанию, которая ежемесячно увеличивает количество серверов, сервисов и расширяет свою инфраструктуру. Со временем этот масштабируемый «технологический ландшафт» становится настолько сложным, что его управление вручную оказывается недостаточно эффективным. Рост компании приводит к увеличению объёмов данных, которые становится невозможно обрабатывать без автоматизированных решений. Возникает вопрос: как обеспечить эффективный контроль за всеми компонентами системы и не допустить критических ошибок?
Современные технологии, такие как облака, микросервисы и интернет вещей, добавляют новые уровни сложности. Эти системы могут демонстрировать непредсказуемое поведение, которое остаётся незаметным до момента возникновения серьёзных проблем. Объём данных стремительно растёт, и без эффективных инструментов легко упустить ключевую информацию.
Что можно сделать:
- Использование масштабируемых инструментов мониторинга, которые адаптируются к росту компании и её инфраструктуры;
- Внедрение единой платформы мониторинга, обеспечивающей централизованный сбор, обработку и анализ данных;
- Автоматизация рутинных операций с помощью скриптов и специализированного программного обеспечения, что позволяет повысить эффективность и минимизировать вероятность ошибок.
Проблема: интеграция и взаимодействие инструментов мониторинга
Представьте, что ваша инфраструктура — это не просто один город, а целый континент с множеством языков и культур. Разные системы мониторинга, каждая из которых специализируется на определённой области (серверы, сети, базы данных), «говорят» на своих языках и предоставляют данные в различных форматах. Это значительно усложняет анализ информации и поиск взаимосвязей. Для обеспечения целостного понимания происходящего становится необходима интеграция этих систем.
Однако объединение данных — лишь часть задачи. Часто инструменты мониторинга пересекаются в своих зонах ответственности, что приводит к избыточности: одно и то же событие может фиксироваться несколькими системами, причём с разными временными метками.
Что можно сделать:
- Установить правила обращения с дубликатами событий;
- Разрабатывать промежуточные решения для нормализации данных из разных источников;
- Найти готовое решение, интегрирующее нужные вам инструменты.
Проблема: перегрузка оповещениями
Избыточное количество уведомлений и поток данных могут привести к игнорированию критически важных сигналов. Когда сотрудники получают слишком много оповещений, их реакция на них становится менее оперативной, увеличивая риск упущения серьёзных проблем. В результате критические сбои могут быть замечены только после жалоб пользователей, что недопустимо для стабильной работы инфраструктуры.
Один из подходов — перестать полагаться исключительно на метки значимости событий и вручную определять правила, что считать важным и как это обрабатывать. Однако такой подход плохо масштабируется, особенно в условиях быстрорастущей инфраструктуры.
Что можно сделать:
- Применять умный отбор важных оповещений, учитывающий не только метку в событии;
- Автоматически уточнять контекст проблемы и находить релевантные события.
Надежда: от реактивного к проактивному IT-мониторингу
Традиционный мониторинг предполагает реактивный подход к управлению инфраструктурой: проблемы фиксируются и устраняются только после их появления. Такой метод сопряжён с риском простоев, которые могут негативно повлиять на бизнес, особенно если сбой становится очевидным лишь на поздних этапах, затрагивая наблюдаемую область системы.
Проактивный мониторинг меняет подход, позволяя выявлять и устранять потенциальные проблемы ещё до их проявления. Кроме того, инструменты предиктивного анализа способствуют не только предотвращению инцидентов, но и упрощению поиска первопричин — устранение неисправностей становится быстрым и точным, если известен их источник.
Что можно сделать:
- Меньше наблюдать за событиями, а больше — за динамической картой системы;
- Внедрить инструменты для предсказания аномалий;
- Устраивать стресс-тесты системе, наблюдая, как именно она даёт сбои, запоминая это на будущее.
Artimate: превращение данных в инсайты

Когда в системе происходит сбой, например, ручное снижение доступной памяти на сервере, начинают накапливаться различные события, которые могут затруднить быстрый анализ проблемы. Российская AIOps-платформа Artimate помогает автоматизировать этот процесс, превращая сырые данные в чёткий инцидент через несколько ключевых этапов:
1. Интеграция и обработка данных
Artimate собирает данные с различных источников, таких как системы мониторинга и лог-агенты. Система обрабатывает эти данные, устраняя дубликаты и оставляя только уникальные события.
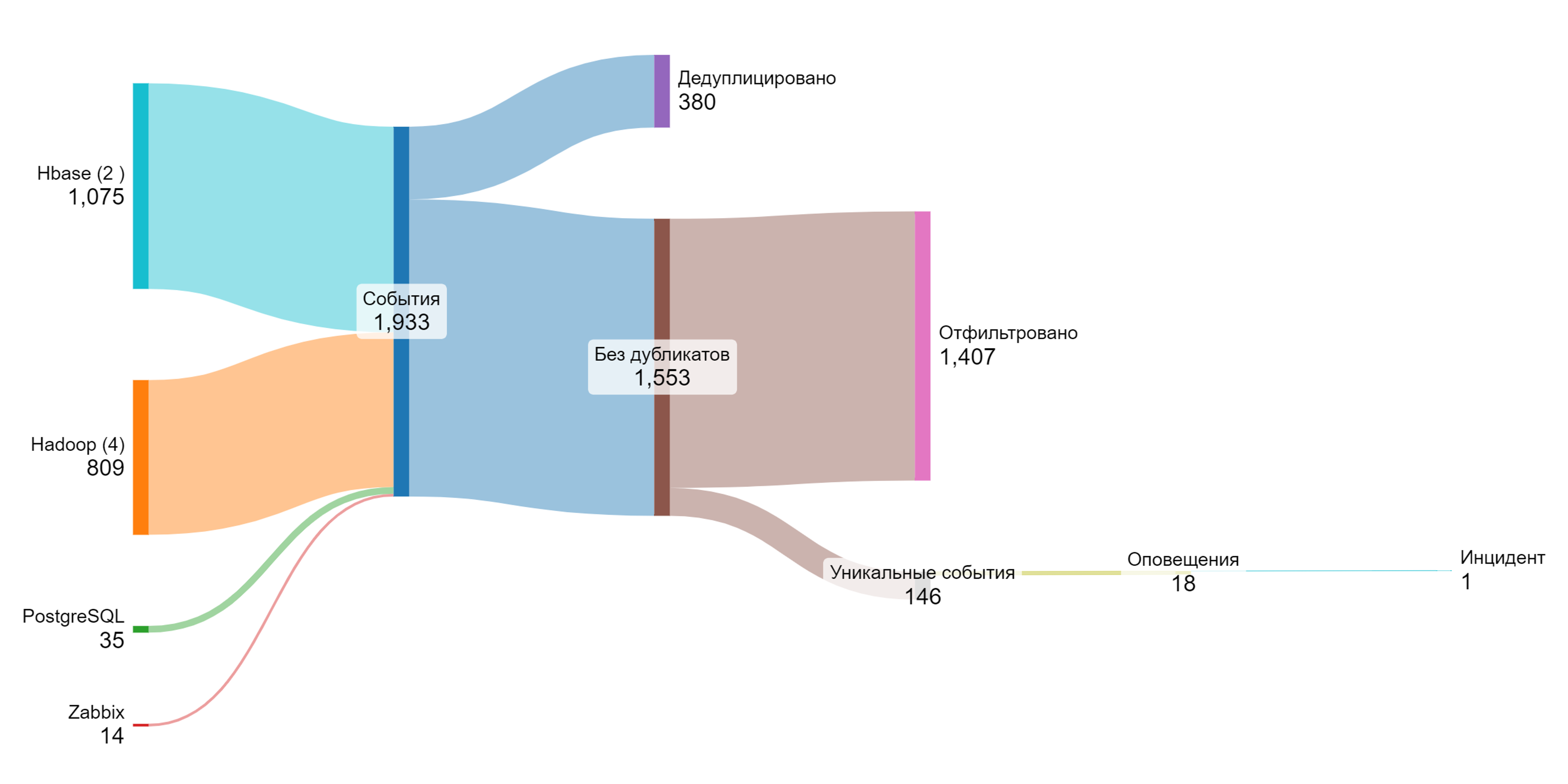
В нашем примере система обработала (ETL) и объединила в один инцидент более 1900 связанных событий из различных источников, включая Zabbix, лог-файлы PostgreSQL, Hbase (2 лог-файла), Hadoop (4 лог-файла). По результатам применения дедупликации, фильтрации было получено 146 уникальных события, агрегированных в 18 оповещений.
2. Управление тегами
Система автоматически присваивает событиям теги для их классификации и упрощения анализа. Часть тегов может быть получена из самих источников данных, другие добавляются на основе знаний о системе. Пользователи могут также вручную добавлять теги для более точной настройки фильтров. Теги помогают быстро организовать и группировать события по важным категориям.
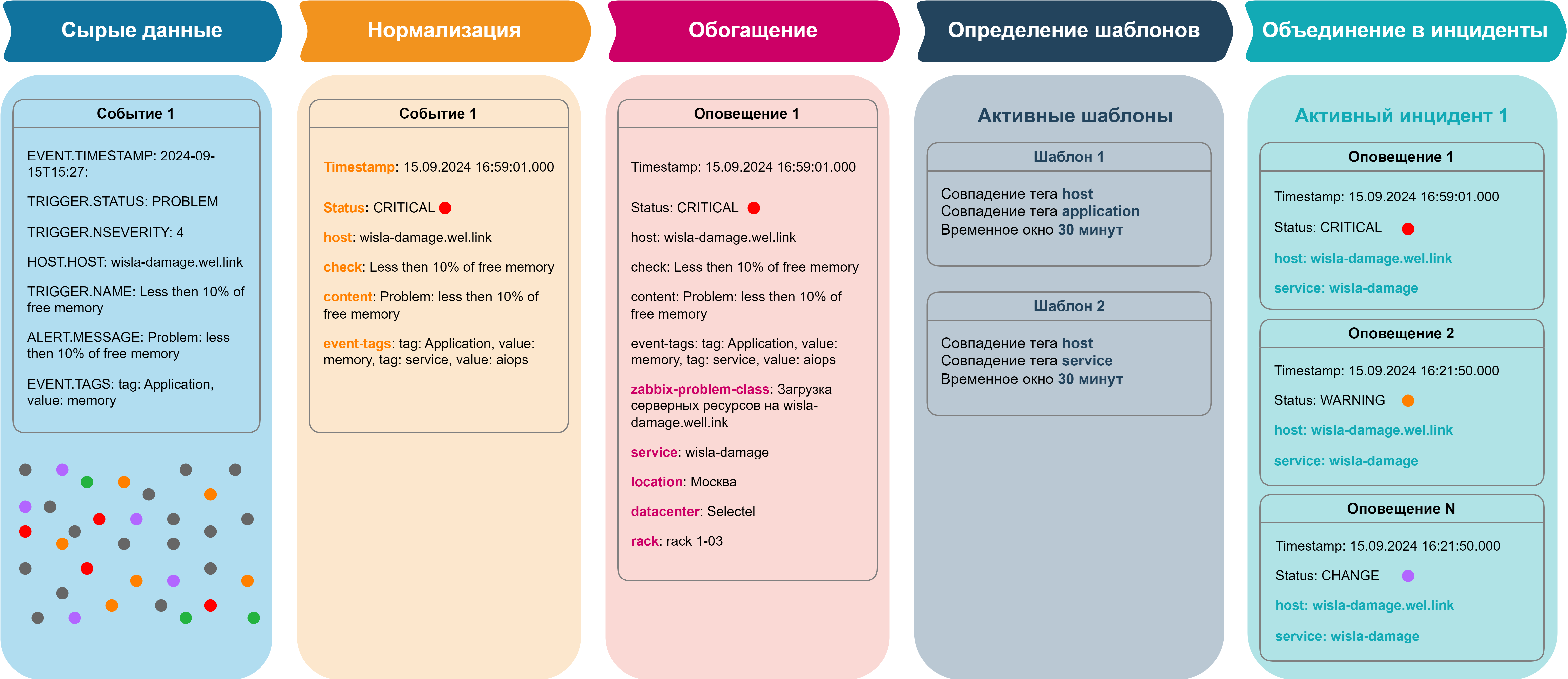
В приведенном примере система автоматически выделила теги из содержания исходного события, обогатила дополнительным контекстом (тегами), таким как service, location, datacenter, rack.
3. Кластеризация и классификация событий
- Система фильтрует события по тегам, отбрасывая те, что не имеют отношения к конкретной проблеме. Это существенно сокращает объём данных, оставляя только релевантные события для анализа.
- AIOps-платформа Artimate использует большие языковые модели для разделения событий по смыслу, группируя их в кластеры. Это помогает выделить различные типы проблем, не работая со множеством отдельных событий.
В нашем примере, после фильтрации по тегам, система оставила ~150 уникальных событий, связанных с проблемой памяти. Затем классификатор сгруппировал их в несколько кластеров по классу проблем, что помогло уменьшить количество сущностей.
4. Анализ паттернов и корреляция
На основе исторических данных, Artimate анализирует взаимосвязи между событиями. Система строит паттерны на основе прошлого опыта, выявляя зависимости между различными кластерами событий и определяя возможные причины проблемы.
В нашем примере система проанализировала корреляции между нехваткой памяти и сбоями в приложениях, используя исторические данные для точного определения первопричины инцидента.
5. Управление инцидентами
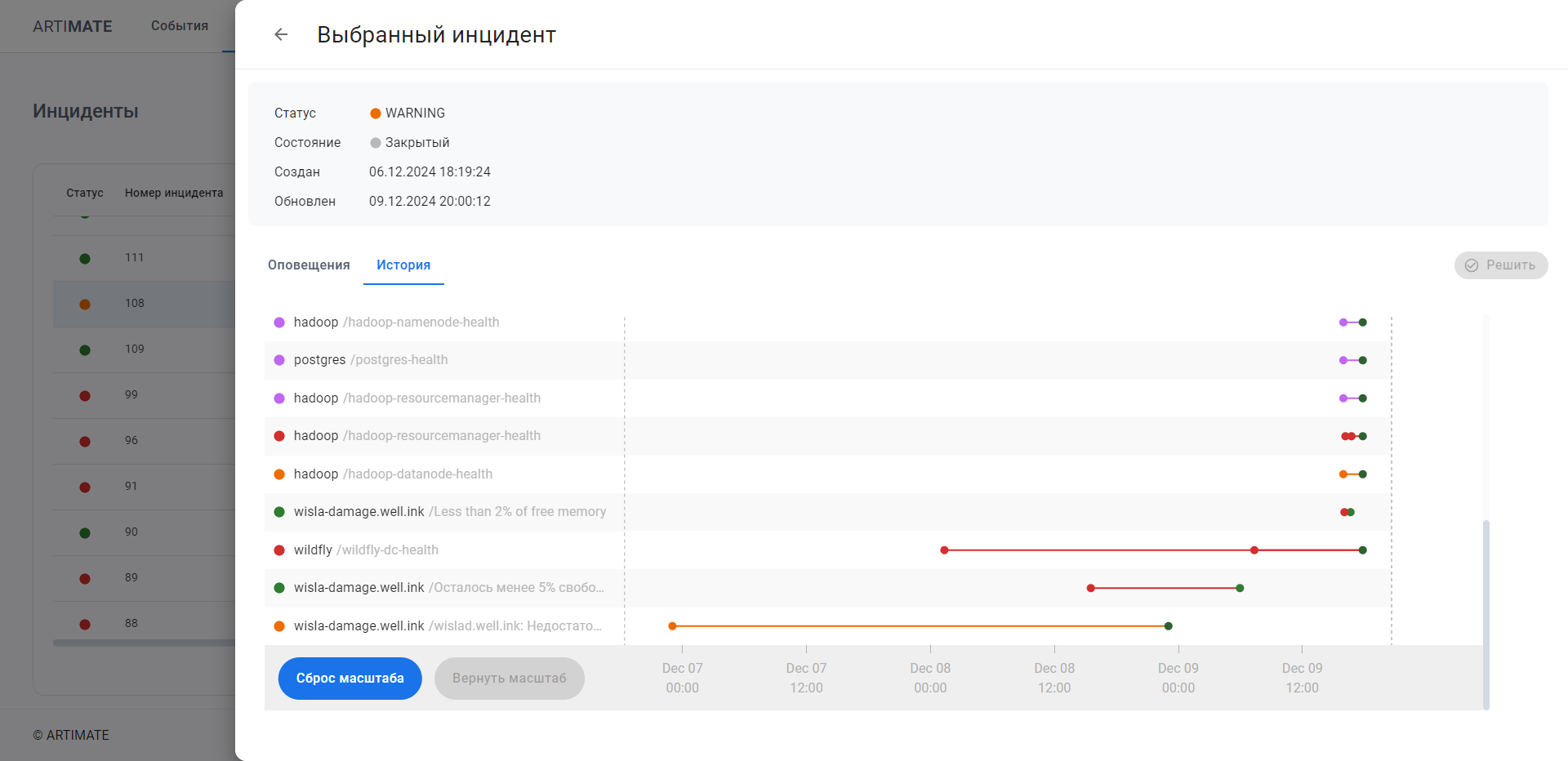
Artimate объединяет все релевантные оповещения события в единый инцидент с помощью алгоритмических и ML шаблонов корреляции, предоставляя в ситуационной комнате всю необходимую информацию для локализации, анализа причинно-следственных связей, истории (Timeline), покрытия ресурсов. Это позволяет быстро получить полное представление о проблеме и приступить к её устранению.
В результате, система объединила все 18 оповещений в один инцидент, связанный с нехваткой памяти, что позволило команде быстро приступить к решению проблемы.
6. Реагирование
AIops-платформа Artimate предоставляет инструменты для эскалации инцидента, доступ к runbook’ам и интеграцию с внешними системами, такими как Service Desk. Это помогает упростить процесс координации между командами и ускорить реагирование на проблему.
В нашем примере инцидент был передан в Service Desk для быстрого решения проблемы, что позволило минимизировать время простоя и предотвратить дальнейшие сбои.
Интеллект и Big Data: сотрудничество во имя эффективности
Используя интеллект (всё больше — машинный и всё меньше — человеческий), мы можем эффективно управлять большими данными и сложными системами. Переход от реактивного к проактивному и интеллектуальному мониторингу — не просто модный тренд, а необходимость в современных условиях экспоненциально развивающихся технологий и языковых моделей. Умение превращать большие объёмы данных в полезные инсайты позволяет компаниям быстрее реагировать на проблемы, оптимизировать работу системы и, в конечном итоге, повышать удовлетворённость пользователей бесперебойной работой.